Подключение локальной LLM к IDEA через Ollama
Уже ни для кого не новость, что нейросети всё больше и больше внедряются в нашу жизнь. И если так пошло и не можешь остановить беспредел — возглавь его, в конце концов. Поэтому сегодня мы развернём Ollama, подключим к ней Qwen и попросим его из IDEA что-нибудь нам написать полезного. Далее примеры и скриншоты будут для установки под Linux, под Windows всё делает инсталляторами.
Ollama
Ollama это программа для запуска LLM (large language model, большая языковая модель). Имеет простой CLI и в целом отвечает большинству простых потребностей.
Сама установка достаточно проста:
$ curl -L https://ollama.com/download/ollama-linux-amd64.tgz -o ollama-linux-amd64.tgz
$ sudo tar -C /usr -xzf ollama-linux-amd64.tgzСоответственно, скачиваем и распаковывем под root’ом архив в /usr. Для проверки выполним запрос версии и увидим следующий ответ:
$ ollama -v
Warning: could not connect to a running Ollama instance
Warning: client version is 0.6.2Что логично, потому что ollama мы не запускали. Можно запустить руками через
$ ollama serveА можно добавить её сервисом. Для этого создадим конфигуацию сервиса и пользователя с группой и добавимся в неё:
$ sudo useradd -r -s /bin/false -U -m -d /usr/share/ollama ollama
$ sudo usermod -a -G ollama $(whoami)
$ sudo nano /etc/systemd/system/ollama.service[Unit]
Description=Ollama Service
After=network-online.target
[Service]
ExecStart=/usr/bin/ollama serve
User=ollama
Group=ollama
Restart=always
RestartSec=3
Environment="PATH=$PATH"
[Install]
WantedBy=multi-user.targetПосле всего обновляем информацию о сервисах, включаем и запускаем сервис:
$ sudo systemctl daemon-reload
$ sudo systemctl enable ollama
$ sudo systemctl start ollamaТеперь проверка версии просто вернёт нам текущую версию Ollama.
LLM
Теперь качаем модель. Тут очень большой простор для выбора. Потому что всё зависит от количества вашей оперативной памяти. Я использую qwen2.5-coder-32b-instruct-q6_k.gguf. Для работы с ноутбука, скажем в такой конфигурации: Core i5 12gen, RAM 16Gb, RTX 3050 я бы брал что-то вроде Qwen-2.5-Coder-7B GGUF Q4 или Q5. Но опять-таки, скачать можно любую модель, вопрос в том, как будет работать
Создаём папочку, где будем хранить скаченные модели:
$ mkdir -p ~/llms/qwen25-coder-32bИ качаем туда модель с https://huggingface.co/Qwen/Qwen2.5-Coder-32B-Instruct-GGUF.
После чего создаём файл Modelfile со следующим содержимым:
$ echo "FROM ./qwen2.5-coder-32b-instruct-q6_k.gguf" > ModelfileЗагружаем модель
$ ollama create my-qwen25-coder -f ModelfileПроверяем, что модель создалась
$ ollama list
NAME ID SIZE MODIFIED
my-qwen25-coder:latest 25c23168b3d4 26 GB 12 seconds ago И запускаем её (чтобы проверить)
$ ollama run my-qwen25-coder
>>> Напиши мне пример hello world на ruby
.
Конечно! Вот простой пример программы "Hello World" на Ruby:
```ruby
puts 'Hello, World!'
```
>>> Send a message (/? for help)Отлично, работает. Переходим к настройке IDEA.
Intellij IDEA
Для того, чтобы подключить Ollama к IDEA нужно установить плагин Continue. Открываем File -> Settings (или просто жмём Ctrl + Alt + S), переходим во вкладку Plugins и ищем и устанавливаем плагин Continue.
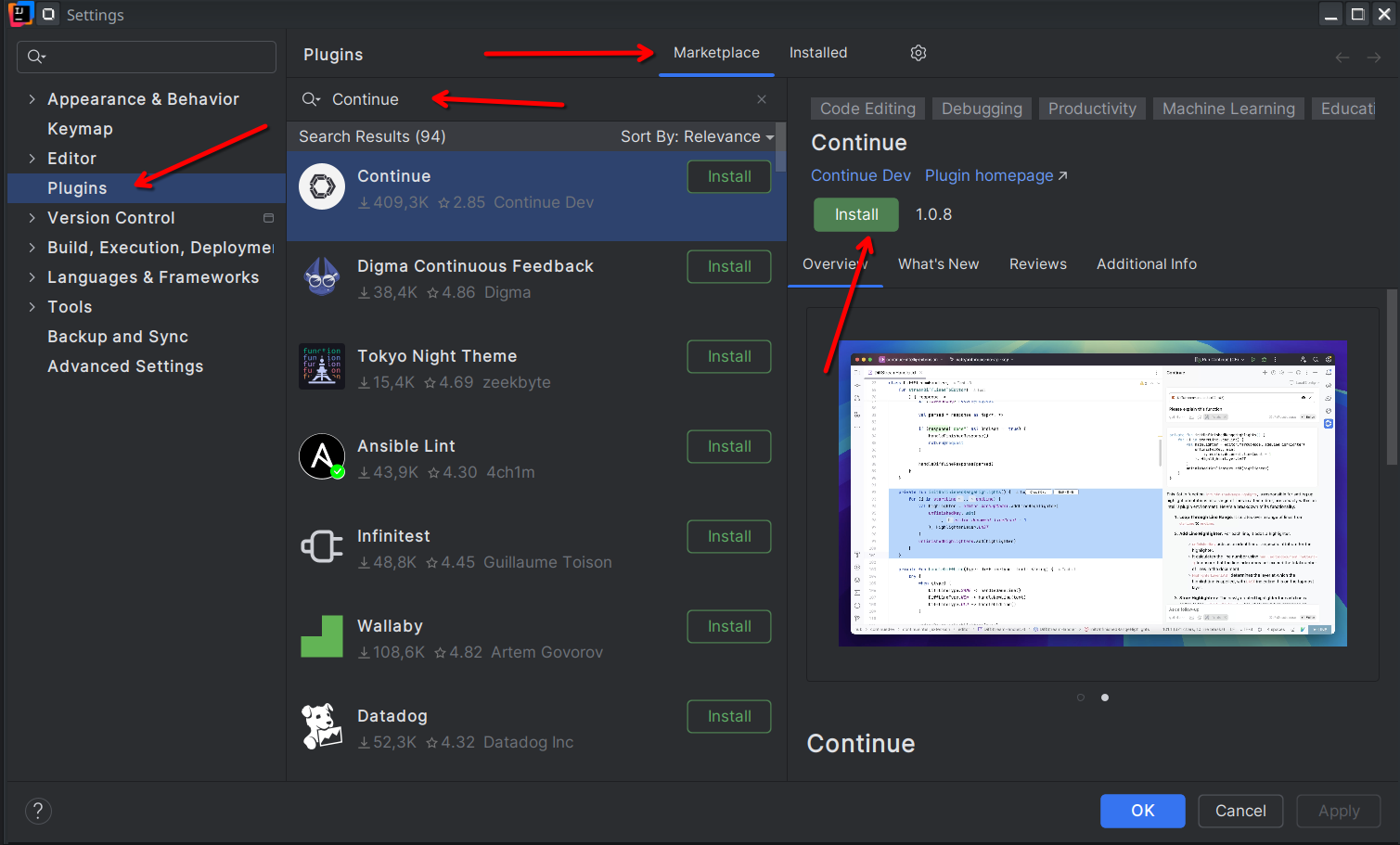
Сразу после установки нам откроется справочный файл, в котором можно посмотреть основные действия.
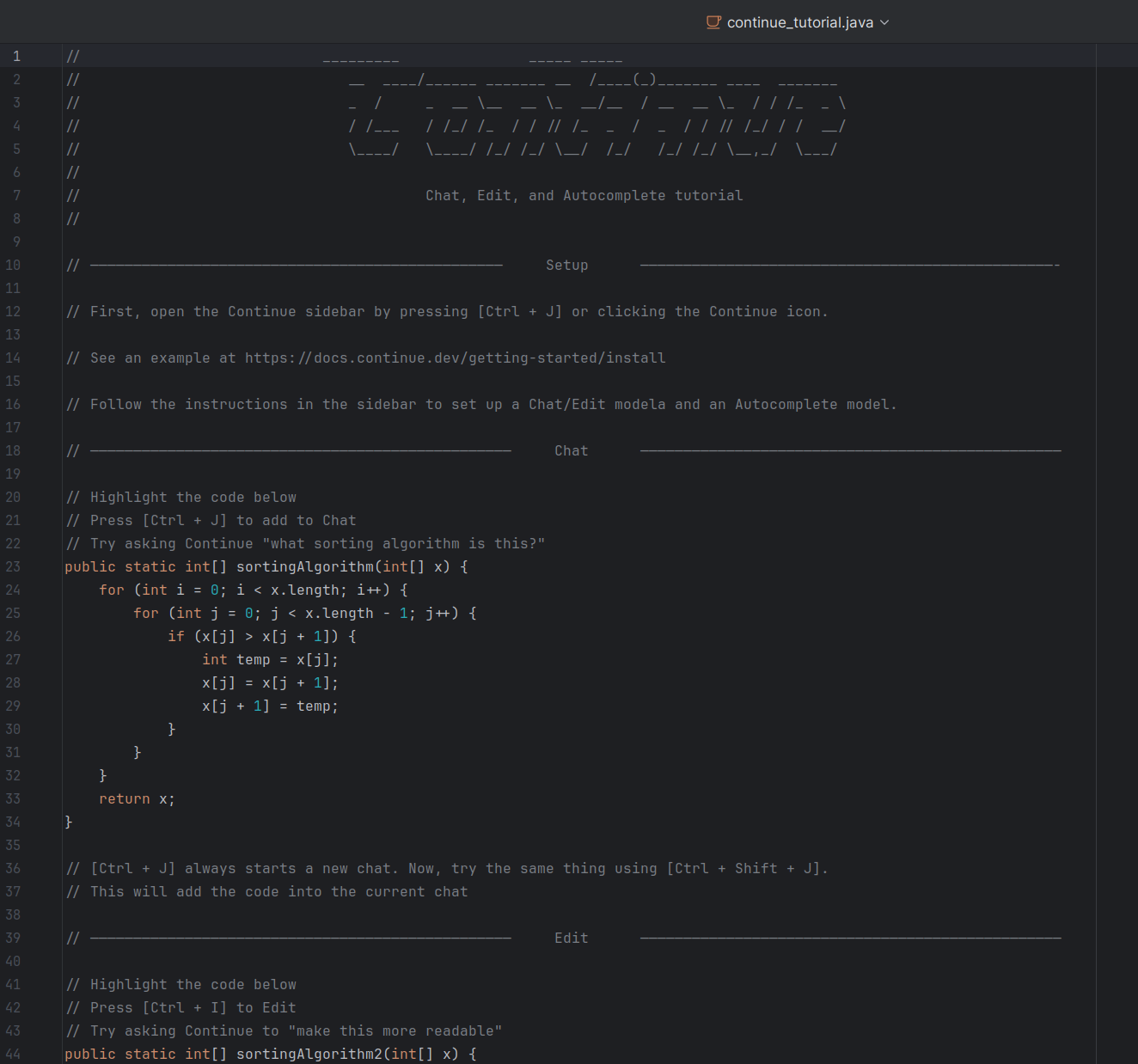
Также, справа в панели появится значок Continue. Нажимаем на него
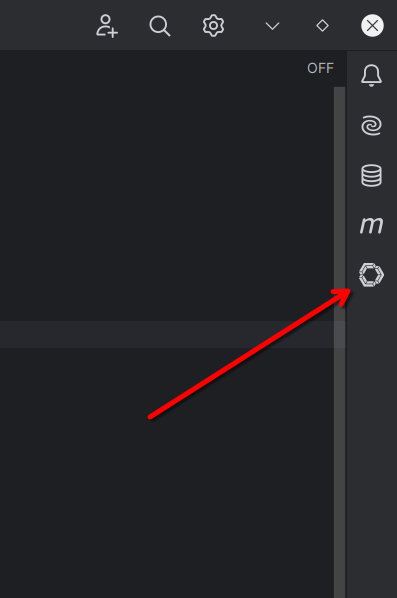
Далее, мы говорим, спасибо, но поработаем локально
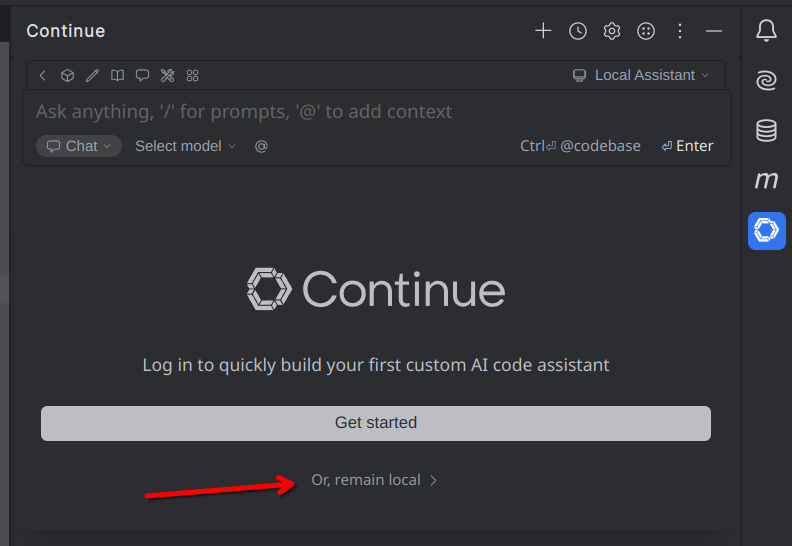
И подключаем через провайдер Ollama нашу модель (она у нас одна, так что можно выбрать autodetect).
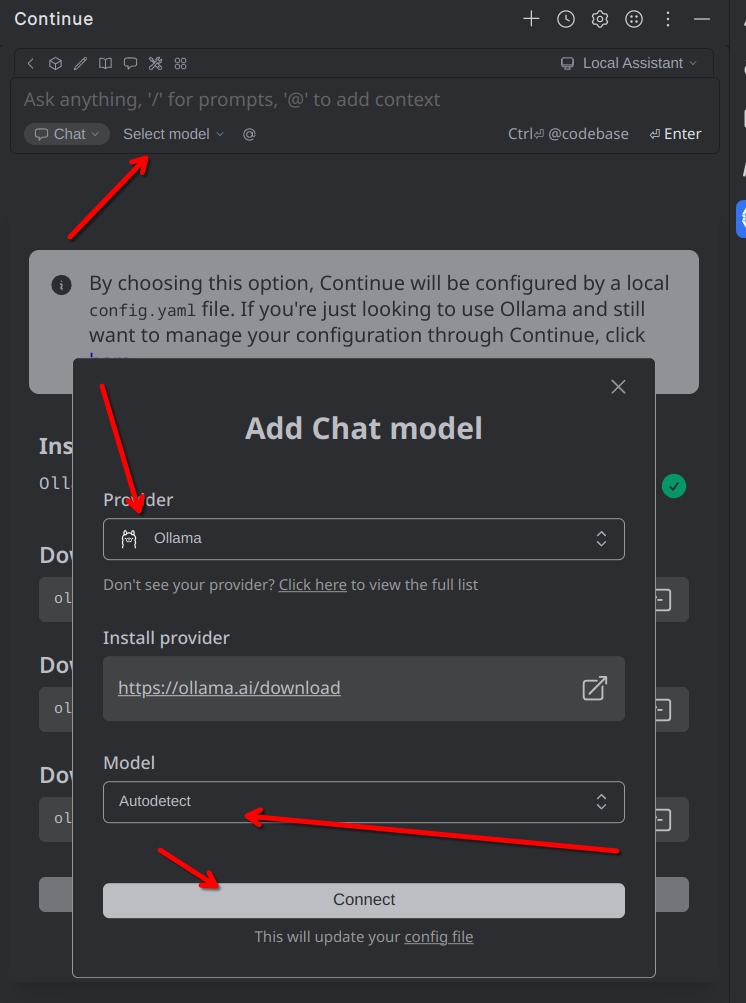
И теперь можем попросить модельку нам сгенерировать небольшой кусочек кода. Нажимаем Ctrl + I, вводим запрос, жмём Enter.
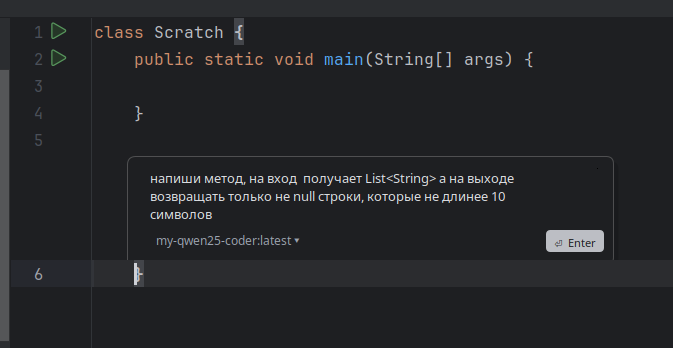
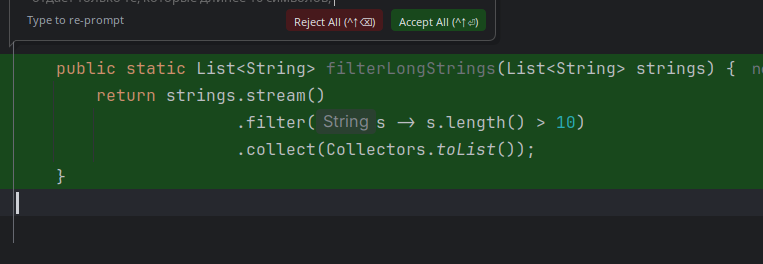
Ждём. Получаем ответ. Если нравится — жмём Ctrl + Shift + Enter, если нет — говорим, что менять.
Картинку для превью этой записи — тоже сгенерил Qwen :)



А если ollama запущена на другом ПК, отдельно от текущего? Т.е. idea на одном, а ии на отдельном, чтобы разграничить ресурсы. Как заставить их работать?
Дополнение: в пределах одной локальной сети.
Привет! Если мне память не изменяет, то там можно указывать хост к api. Можно его указать и будет ходить по сети. Я просто отказался от этого решения, так как всё ж нужна тачка помощнее